

【儀表網 研發快訊】近日,南方科技大學深港微電子學院余浩教授研發團隊在具身智能硬件領域取得多項突破性成果。團隊共發表3篇期刊論文,分別發表在集成電路設計領域期刊《固態電路雜志》(IEEE Journal of Solid-State Circuits, JSSC)、電路與系統領域期刊 IEEE Transactions on Circuits and Systems I: Regular Papers 、電路與系統領域期刊《集成電路與系統》(IEEE Integrated Circuits & Systems, ISC)上。
基于矢量脈動的高能效深度神經網絡加速器,突破傳統AI芯片設計中“能效-面積-靈活性”三角矛盾
團隊提出了基于矢量脈動的高能效深度神經網絡加速器。相關成果以“A 29.12 TOPS/W Vector Systolic Accelerator with NAS-optimized DNNs in 28-nm CMOS”為題被集成電路設計領域期刊《固態電路雜志》(IEEE Journal of Solid-State Circuits, JSSC)接收。
隨著大模型時代的到來,深度神經網絡模型的算力需求呈指數級增長,但傳統芯片架構面臨能效與性能的雙重瓶頸。研究團隊針對這一挑戰突破傳統AI芯片設計中“能效-面積-靈活性”三角矛盾,實現了三大技術創新:動態精度調控:打破固定精度限制,在能效與準確率間實現動態平衡;結構化稀疏編碼:通過對數尺度稀疏策略,在壓縮率提升30%的同時保持模型精度;矢量脈動陣列:創新的脈動架構將內存帶寬利用率提升至92%,顯著降低數據搬運能耗。

圖1.1 基于4-bit的矢量處理單元(SCV PE)中實現8-bit的組合和2-bit/1-bit的拆分運算
圖1.1展示了基于拆分和組和矢量(SCV)的動態精度調控的混合精度加速器,該加速器利用在每一層復用可變精度單元矢實現1-bit、2-bit、4-bit和8-bit精度的計算,并進一步采用實現脈動陣列(VSA)實現更大規模的集成,以提升芯片的吞吐量。芯片在對 NSA 優化的混合精度 VGG-16 模型測試中,實現了平均能量效率達到29.12 TOPS/W(等效于2-bit精度的高能效),模型的推理準確率達到70.146%(等效于4-bit精度模型的高準確率)。該研究實現了很好的能效和面積效率,且實現了模型的低成本和高能效部署。

圖1.2 動態精度調控加速器芯片測試
圖1.2展示了動態精度調控芯片的測試環境及結果,實驗結果標明該論文設計的芯片與目前國際最先進的研究工作相比,基于矢量的可拆分與組合實現的混合精度實現了最高的峰值能效(63.54 TOPS/W)和最高的峰值面積效率(7.94 TOPS/mm2)。
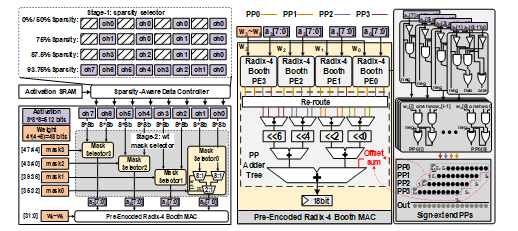
圖1.3 對數尺度的結構化稀疏編碼策略以及混合稀疏的 Booth MAC 設計
圖1.3展示了提出的對數尺度的結構化稀疏編碼策略,本工作同時結合混合稀疏的 Booth 算法的 MAC 單元以及組矢量脈動陣列(G-VSA)來優化提高系統性能和能效。該混合加速器芯片采用28-nm CMOS 工藝,在工作電壓為0.7V和工作頻率為400MHz時,實現了平均能量效率高達 21.7 TOPS/W 的模型部署能效。測量結果顯示,該混合稀疏芯片在能量效率和準確性方面均優于當前先進的稀疏芯片。

圖1.4 混合稀疏加速器的芯片測試
圖1.4展示了混合稀疏芯片的測試環境及結果。在0.6V到1V的運行電壓下,芯片頻率從199 MHz變化到986 MHz,大約比先前的先進工作高出約2.5倍,這得益于 G-VSA 和優化的混合稀疏 MAC 設計。加速卷積層的峰值吞吐量在1V時達到4.04 TOPs。在不同的供電電壓下,能耗范圍從26mW到314mW,對應的能效為1.67到31.26 TOPS/W。

圖1.5 具有混合精度及稀疏的立方脈動架構芯片的性能比較
論文對基于立方脈動架構的混合精度和混合稀疏芯片,在相同測試用例的條件下進行了公平的比較,如圖1.5所示,混合精度 VSA 在相似的準確度水平上展示了更優越的能量效率,而混合稀疏模型則實現了更優的模型壓縮效果。因此,對于內存限制嚴重的場景推薦使用混合稀疏模型,而當能量效率和準確度是主要考慮因素時,則混合精度加速器更為合適。
2021級博士生李凱為論文第一作者,余浩為論文的唯一通訊作者,南方科技大學為論文的第一單位。該論文得到了國家科技重點研發計劃項目和孔雀團隊項目經費的支持。
成功部署端側 FPGA 大模型推理系統,攻克大語言模型(LLM)在資源受限邊緣設備上的部署難題
研發團隊與深圳市邁特芯科技有限公司合作,進一步攻克大語言模型(LLM)在資源受限邊緣設備上的部署,利用已驗證的混合精度計算單元以及立方脈動陣列架構,成功部署了多個 7B LLM 語言模型及多模態模型。與GPU相比,該系統的吞吐量提高了1.91倍,能效提高了7.55倍;與最先進的 FPGA 加速器 FlightLLM 相比,整體性能提升了10%到24%。相關研究成果以“EdgeLLM: A Highly Efficient CPU-FPGA Heterogeneous Edge Accelerator for Large Language Models”為題發表在 IEEE Transactions on Circuits and Systems I: Regular Papers 上。

圖2.1 端側大模型推理卡
為了將大語言模型在資源受限的端側系統部署,團隊解決了幾大困難挑戰。首先,大語言模型計算量龐大以及內存訪問需求極高,現有解決方案通常將這些權重參數量化為 INT4 格式。為了確保計算精度,模型中的激活函數仍然保持 FP16 格式。因此,在前饋神經網絡(FFN)層中,系統需要支持 FP16INT4 格式的矩陣乘法。另一方面,在多頭注意力(MHA)模塊中,KV緩存作為激活數據動態生成,涉及KV緩存的矩陣乘法需要 FP16FP16 格式。因此,團隊沿用混合精度的思路,定制化實現了FP16INT4以及 FP16FP16 的混合精度計算單元以加速 LLM。團隊分析了前饋網絡(FFN)和多頭注意力(MHA)的計算需求,在高效率的混合精度計算單元的基礎上,構建了立方脈動陣列架構以進一步提升計算密度。團隊還提出了對數尺度結構化稀疏性和塊級量化方法,以在硬件效率和算法精度之間取得平衡。
此外,在大語言模型中,定義計算流程的算子圖極其復雜,包含數百甚至數千個以復雜方式相互連接的算子,確保從一個算子到另一個算子的過渡無縫且高效成為了一項重大挑戰。團隊分析了大語言模型中的編譯需求,設計了一種統一且通用的數據格式,適用于所有算子和AI算法中的高維張量結構,使系統能夠快速執行算子操作而無需任何數據重排。隨后,開發了端到端的編譯方案,其中動態編譯用于處理不同輸入 token 長度,指令流水線策略用于減少延遲。該方案能夠動態編譯所有算子,并將整個模型映射到 CPU-FPGA 異構系統上。

圖2.2 不同端側大模型推理卡對比
南方科技大學深港微電子學院2023級碩士生申奧同與中國科學院深圳先進技術研究院黃明強研究員同為第一作者,余浩為論文的唯一通訊作者,南方科技大學為論文的通訊單位。該研究得到了醫學成像科學與技術系統全國重點實驗室、科技創新2030重大科技項目的資助。
進行LLM 具身智能 NGS 研究,促成具身智能系統應用落地
研發團隊還為解決大語言模型的具身智能系統應用落地提供了解決方案,相關成果以“emGene: An Embodied LLM NGS Sequencer for Real-time Precision Diagnostics”為題發表在電路與系統領域期刊《集成電路與系統》(IEEE Integrated Circuits & Systems, ISC)上。
余浩團隊聯合上海芯像生物科技有限公司合作研發了 LLM 具身化的 NGS 測序儀-emGene,優化后的大語言模型得以在端側大模型推理卡上高效部署,使診斷流程大幅提速,從而實現實時、現場 DNA 分析,在醫療領域實現實時、現場基因智能診斷的實際應用。

圖3.1 emGene大語言模型(LLM)邊緣 NGS 測序儀
精準醫療正在革新全球醫療保健,通過實現個性化診斷、疾病預測以及定制化治療策略,極大地提升了醫療水平。雖然基因組學與數據科學的整合蘊藏著優化精準治療效果的巨大潛力,如何將基因測序數據轉化為可應用于體外診斷的洞察力仍是一個關鍵挑戰,這一瓶頸主要源自邊緣側智能處理和自動化能力的局限。盡管基因測序技術和生物信息學工具不斷進步,從樣本采集到診斷報告生成的工作流程依然零散、低效且缺乏智能化支持。
為了解決這些問題,團隊提出了一款 emGene 大語言模型(LLM)的邊緣NGS測序儀(圖3.1),實現實時、現場智能基因診斷。該儀器整合了一個高效且全面的 emGene 處理流水線。采用深度學習網絡進行初步數據分析,利用機器學習實現二次數據處理,并通過經過量化與壓縮優化的大語言模型完成三階數據解讀。借助于 FPGA 部署,該方案加速了診斷流程。實驗結果顯示,其通量提高了13.72%,Q30達到了99.50%,并且在邊緣側實現了高達75 token/s 的智能診斷性能。


圖3.2 emGene 一二三階段處理流水線
研發團隊開發了一整套先進的 emGene 數據分析系統,以提升 NGS 設備上 DNA 測序的表現:在一階分析中,團隊利用深度學習構建了高通量簇檢測模型,通過優化 CNN 和 Transformer 模型實現卓越的堿基識別,實現了較低的錯誤率、提高了數據質量、增加了吞吐量并加快處理速度;在二階數據分析中,團隊整合了機器學習模型,來提高變異檢測的精度;同時,在三階數據分析中并利用向量數據庫和提示學習技術將領域特定的DNA知識嵌入大語言模型中,為各種應用提供智能報告解讀。最后,團隊采用了 CPU-FPGA 異構加速框架優化邊緣設備上部署量化大語言模型(LLMs)的性能。該 FPGA 實現整合了多項定制優化措施,包括 FP16*INT4 和 FP16I*FP16 計算引擎、脈動計算陣列、結構化稀疏等技術。這些優化均針對 LLMs 特有的數據格式量身定制,顯著提高了 FPGA 在邊緣部署時的效率。

圖3.3 emGene一二三階段處理流水線結果
圖3.3展示了深度學習在一階數據分析模塊超越了傳統方法性能:其平均處理速度快19%,檢測到的簇數量多13.72%,且平均Q30 >99.50%。在二階數據分析中,F-1 Score 超越了其他設備處理結果。在三階數據分析方面,通過引入 ChatGLM2-6B 模型和提示學習技術,在邊緣設備上經過 INT8 量化后,準確性和速度均獲得了顯著提升,達到71.64%的精度,且性能最高可達75 tokens/s。
本研究工作使得實時邊緣基因數據分析成為可能,從而大幅提升了精準醫療的可及性和效率,同時顯著提高了診斷準確性和自動化水平,為人工智能驅動的個性化醫療構建了一個穩健平臺,并為未來的醫療服務設定了全新的標桿。
余浩為論文的通訊作者,南方科技大學為論文的第一單位,該論文得到了國家科技重點研發計劃項目和孔雀團隊項目經費的支持。




















所有評論僅代表網友意見,與本站立場無關。